for i in {1..3}; do
docker-machine create --driver=virtualbox swarm-node-$i
doneDocker Swarm Mode Health Checks
TLDR;
-
Die Sourcen sind unter : https://github.com/effective-docker/docker-healthcheck.git
-
Swarm Scheduler arbeitet mit den Container Health Checks
-
Nur healthy Container werden geroutet.
-
Nach drei fehlgeschlagenen Health-Checks wird ein Container neu gestartet (ggf. auch auf einem anderen Knoten)
Docker Swarm Mode
Im letzten Eintrag haben wir uns mit Health Checks in Containern beschäftigt. Das alleine ist schon eine sehr wichtige Funktionalität, entwickelt ihr Potential allerdings erst in Zusammenarbeit mit einem Scheduler der das aktiv unterstützt. In diesem Artikel konzentrieren wir uns auf Docker Swarm im Swarm Mode (ab 1.12)
Swarm Mode ist das neue Swarm integriert in die Docker Engine - nicht zu verwechseln mit Docker Swarm (Standalone), was vor 1.12 aktuell war.
Im folgenden arbeiten wir der Einfachheit halber mit VirtualBox und Docker-Machine.
Zunächst setzen erstellen wir uns einen Stack mit 3 Nodes.
|
Tipp
|
Die Anzahl an Nodes im Schwarm sollte nach Möglichkeit ungerade sein, damit man einfache Mehrheiten bilden kann. |
|
Tipp
|
Wenn wir die Maschinen mit docker-machine erstellen sind bereits alle Zertifikate richtig konfiguriert. |
Zunächst prüfen wir, ob die Knoten korrekt erstellt und gestartet sind.
docker-machine ls
swarm-node-1 - virtualbox Running tcp://192.168.99.101:2376
swarm-node-2 - virtualbox Running tcp://192.168.99.102:2376
swarm-node-3 - virtualbox Running tcp://192.168.99.103:2376Mit den einzelnen Knoten können wir uns jetzt über die Docker Remote-API verbinden.
Wir machen die Knoten 1 und 2 zu Swarm-Managern.
#connect to node 1
eval $(docker-machine env swarm-node-1)
docker swarm init --advertise-addr $(docker-machine ip swarm-node-1)
# connect to node 2
eval $(docker-machine env swarm-node-2) (1)
# join swarm as worker
docker swarm join --token <token> $(docker-machine ip swarm-node-1):2377 (2)
# connect to node 3
eval $(docker-machine env swarm-node-3)
# join swarm as worker
docker swarm join --token <token> $(docker-machine ip swarm-node-1):2377 (3)
# promote node-2
docker node promote swarm-node-2
Node swarm-node-2 promoted to a manager in the swarm. (4)
# status
docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
kr5m52gdhx3ky7enck5ifjd27 swarm-node-2 Ready Active Reachable
qb2llmor6n5hogv3ql1pudl7d * swarm-node-1 Ready Active Leader
wr708u31k6uxogn0u66ykh61n swarm-node-3 Ready ActiveDie Kommunikation im Swarm muss immer über einen Manager geschehen, denn nur Manager haben die Befugnis Entscheidungen treffen.
Beispielanwendung
Wir arbeiten erneut mit der einfachen Health-Check Spring Boot Applikation aus dem letzten Artikel.
Zusätzlich deployen wir den Swarm-Visualizer um den Schwarm zu sichtbar zu machen.
docker service create \
--name=viz \
--publish=9000:8080/tcp \
--constraint=node.role==manager \ (1)
--mount=type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock \
manomarks/visualizer-
Der Visualizer muss auf einem Manager laufen
Prüfen Sie mit docker service ls wann der Visualizer bereit ist.
docker service ls
mbkr330h65kh viz replicated 0/1 manomarks/visualizer:latest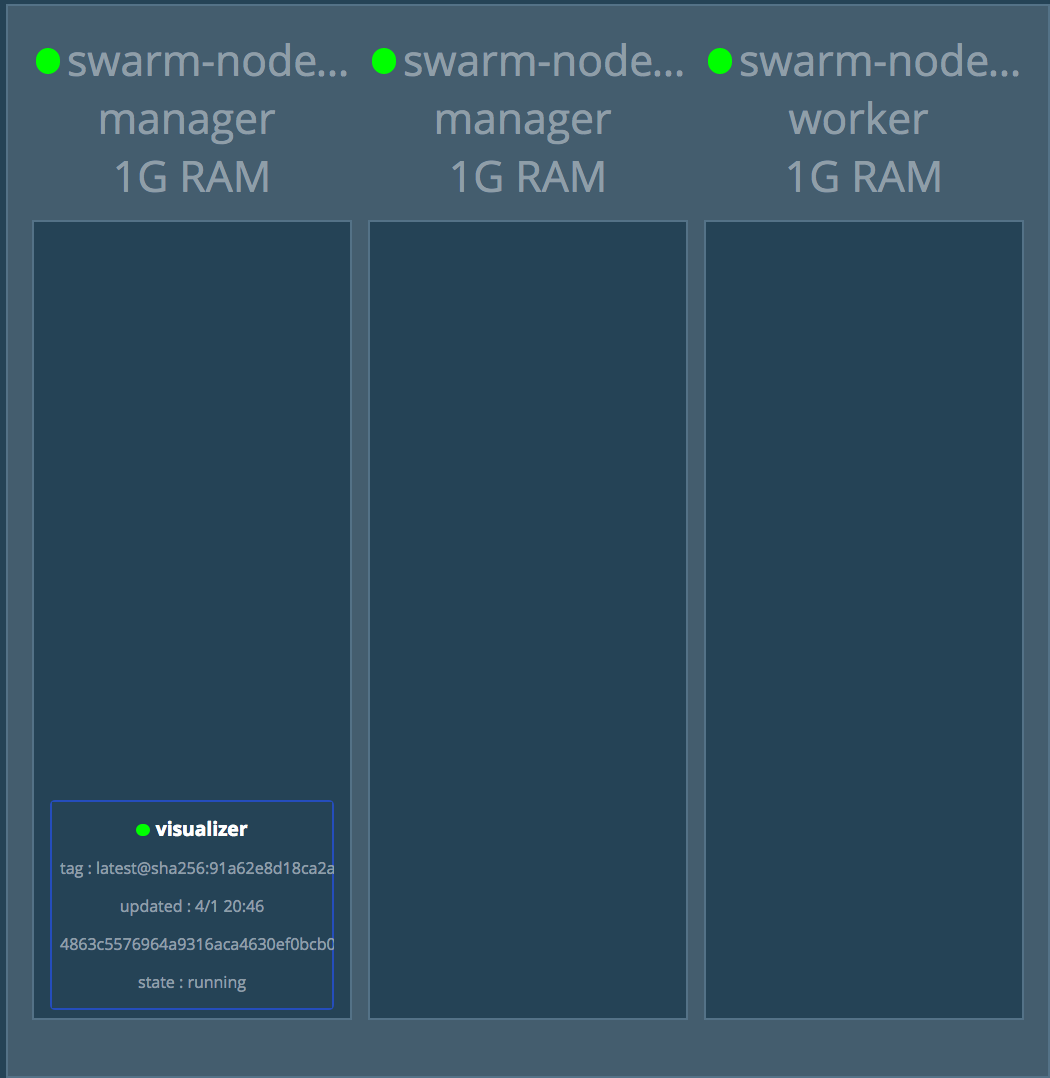
Deployen Sie anschließend die Health-Applikation als Service mit zwei Replicas.
#connect to manager
eval $(docker-machine env swarm-node-1)
docker service create --health-cmd "curl -f http://localhost:8080/health || exit 1" --name health --replicas 2 -p 8080:8080 effectivetrainings/docker-health
#status
docker service ps viz
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE
ymzuujcd6awr viz.1 manomarks/visualizer:latest swarm-node-1 Running Preparing
Docker Health Check
Nachdem die Services deployt sind machen wir uns erneut die Möglichkeit zunutze, den Health-Status der Anwendung manuell zu setzen. Wir setzen eine Service-Instanz auf unhealthy.
curl $(docker-machine ip node-3):8080/environment/health?status=false|
Achtung
|
Achtung, wir setzen hier die Umgebungsvariablen von Node-3. Es ist aber nicht definiert, welcher Container wirklich angesprochen wird. Das entscheidet Docker intern über den DNS-Server. |
Docker Swarm überwacht ständig den Status der Services / Tasks im Cluster und re-scheduled Container wenn nötig.
Standardmäßig versucht Swarm dreimal den Health-Check durchzuführen, nach dem dritten gescheiterten Versuch wird der Container neu gestartet.
Zusätzlich werden nur Container geroutet, die Healthy sind. Sobald ein Container unhealthy ist und der Manager dies erkennt wird er nicht mehr angesprochen.
Fazit
Speziell im Swarm machen die Container Health Checks Sinn, da Swarm Container nicht routet, die unhealthy sind. Die Verwendung ist wie immer denkbar einfach und funktioniert erstaunlich stabil und gut.
Docker Training
Wollen Sie mehr erfahren? Ich biete Consulting / Training für Docker. Schauen Sie doch mal vorbei!