for i in {1..3}; do docker-machine create --driver virtualbox node-$i; done;Chaos Testing
In verteilten Systemen können wir Fehler niemals ausschließen. Die möglichen Fehlerquellen sind fast unendlich.
-
partieller oder totaler Netzwerkausfall
-
Datenbankprobleme
-
Anwendungen / Services sind kurzfristig / langfristig nicht verfügbar
-
Lastprobleme
-
Sicherheit / Firewall / ungültige Zertifkate
Resilient Software sollte so geschrieben sein, dass Fehler akzeptiert werden und der Aufrufer noch zumindest teilweise das System bedienen kann.
Netflix hat mit seiner Werkzeug-Box SimianArmy Tools für das Chaos-Testing erstellt und damit Chaos-Testing salonfähig gemacht. Chaos-Testing folgt den Prinzipien des Chaos. Beispielsweise fährt Chaos-Monkey durch Zufall ausgewählte Server-Instanzen herunter, genau wie ein Affe, der wahllos Kabel zieht.
Warum macht Netflix das? Weil nur dann sichergestellt ist, dass ein System auch dann funktioniert, wenn Upstream-Services nicht verfügbar* sind. Ein Entwickler kann sich niemals darauf verlassen, dass der Service, den er gerade aufruft auch verfügbar ist - Chaos.
TLDR;
-
Mit Pumba lassen sich Chaos-Tests in einer Docker / Swarm Umgebung ausführen. Pumba kann:
-
Container stoppen
-
Pausieren
-
Netzwerk Pakete verwerfen
-
Netzwerk Pakete neu ordnen
-
Netzwerk Pakete zurückhalten '''
Docker Swarm Setup
Zunächst setzen wir den Schwarm wie gehabt mit Virtual Box auf, um schnellstmöglich ein einfaches Test-Szenario zu haben. Zunächst erstellen wir uns drei Nodes.
|
Tip
|
Üblicherweise wird eine ungerade Anzahl an Nodes in einem Cluster verwendet. Wissen Sie warum? |
Dann initialisieren wir den Schwarm, machen node-1 und node-2 zu Managern, node-3 ist ein einfacher Worker.
export manager=node-1
eval $(docker-machine env $manager)
docker swarm init --advertise-addr $(docker-machine ip $manager)
export token=$(docker swarm join-token -q worker)
for i in {2..3}; do
eval $(docker-machine env node-$i)
docker swarm join --token=$token $(docker-machine ip node-1)
doneWir starten wie immer den Swarm-Visualizer, um besser zu verstehen was passiert.
docker service create \
--name=viz \
--publish=9000:8080/tcp \
--constraint=node.role==manager \
--mount=type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock \
manomarks/visualizer|
Tip
|
Die URL bekommen Sie über 'echo "http://$(docker-machine ip $manager):9000"', bei mir http://192.168.99.100:9000 |
Im nächsten Schritt schedulen wir einige Services, die nichts weiter machen ausser sich gegenseitig aufzurufen. Das Image, dass wir hierfür verwenden ist effectivetrainings/rest-cascade. Diese Image beinhaltet eine einfache Spring-Boot Anwendung mit einem Rest-Endpoint.
docker network create --driver overlay test (1)
# erster service
docker service create -p 8080:8080 --network test --name service-1 -e targetUri=http://service-2:8080 effectivetrainings/rest-cascade (1)
for i in {2..4}; do
docker service create --network test --replicas=2 --name "service-$i" -e targetUri=http://service-$(($i+1)):8080 effectivetrainings/rest-cascade
done;
docker service create --network test --name service-5 effectivetrainings/rest-cascade (1)-
Wir definieren ein Netzwerk, damit die Services im Schwarm über DNS kommunizieren können
-
Über die Umgebungsvariable targetUri sagt man dem Service, dass er weitere Services aufrufen soll, wenn er angesprochen wird. Eine Kaskade eben.
-
Der letzte Service beendet die Kaskade
Warten wir, bis alle Services gestartet sind.
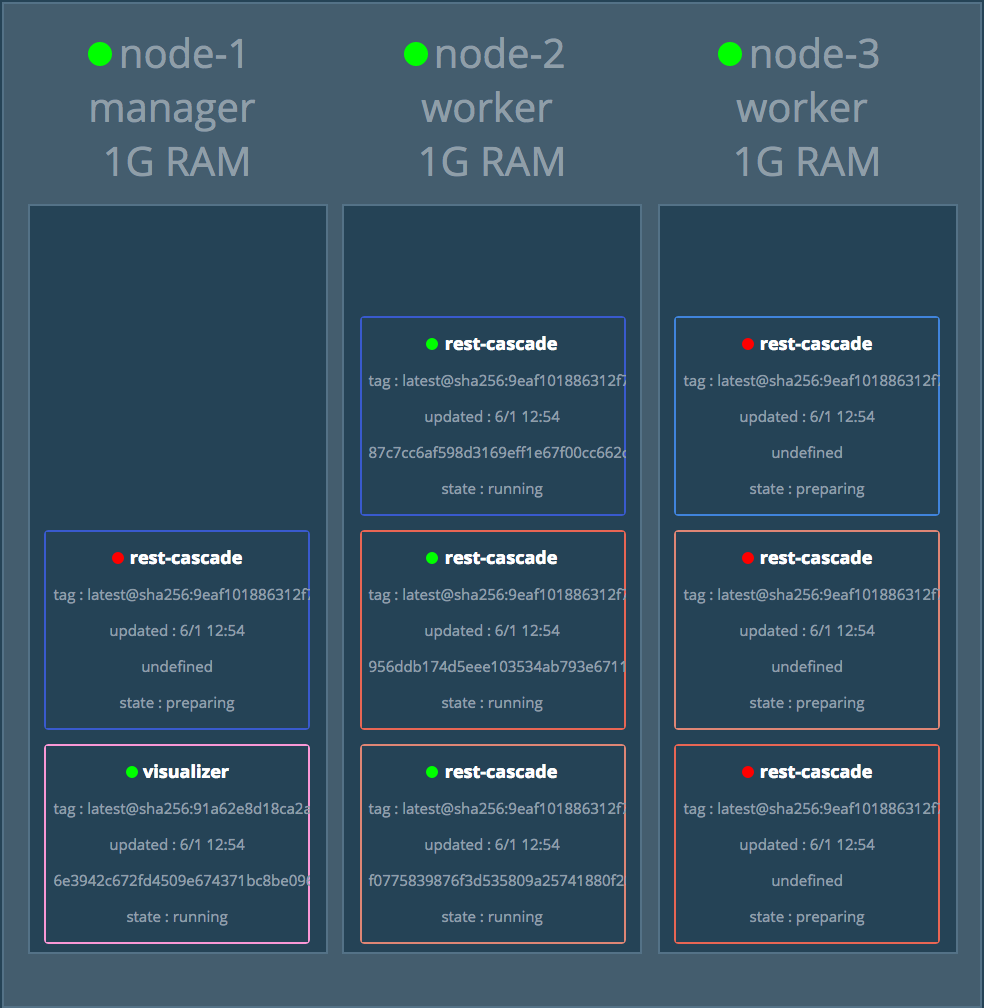
Der einzige Service, der von außen angesprochen werden kann ist node-1, da nur dieser einen Port exposed. Der Service fungiert als unser Gateway.
Rufen wir den Service mit einem einfachen cURL auf, sollte die Response uns sagen, welche Services in der Kommunikation beteiligt waren.
curl $(docker-machine ip node-1):8080
{
"host": "d6d431be03f4",
"port": 8080,
"correlationId": null,
"responseInfo": {
"host": "d186a4430a59",
"port": 8080,
"correlationId": null,
"responseInfo": {
"host": "aa404c0b20eb",
"port": 8080,
"correlationId": null,
"responseInfo": {
"host": "9ba048210be9",
"port": 8080,
"correlationId": null,
"responseInfo": {
"host": "c57154d95c3c", (1)
"port": 8080,
"correlationId": null,
"responseInfo": null,
"msg": null
},
"msg": null
},
"msg": null
},
"msg": null
},
"msg": null
}-
Antworten aus Sicht des Aufrufers - in diesem Fall service-4 ruft service-5. Die Antwort kam von Host c57154d95c3c.
Zur Verifikation betrachten wir Service-5 etwas genauer.
docker inspect --format {{.Status.ContainerStatus}} $(docker service ps -q service-5)
{c57154d95c3c8e3ba3954a53649c9c3d0550ad0d4ac5c64fb410a8efe7038270 7512 0}Hier sehen wir, service-5 arbeitet tatsächlich mit der Container-ID c57154d95c3c8e3ba3954a53649c9c3d0550ad0d4ac5c64fb410a8efe7038270.
Die Service bilden also akutell folgende Kaskade.
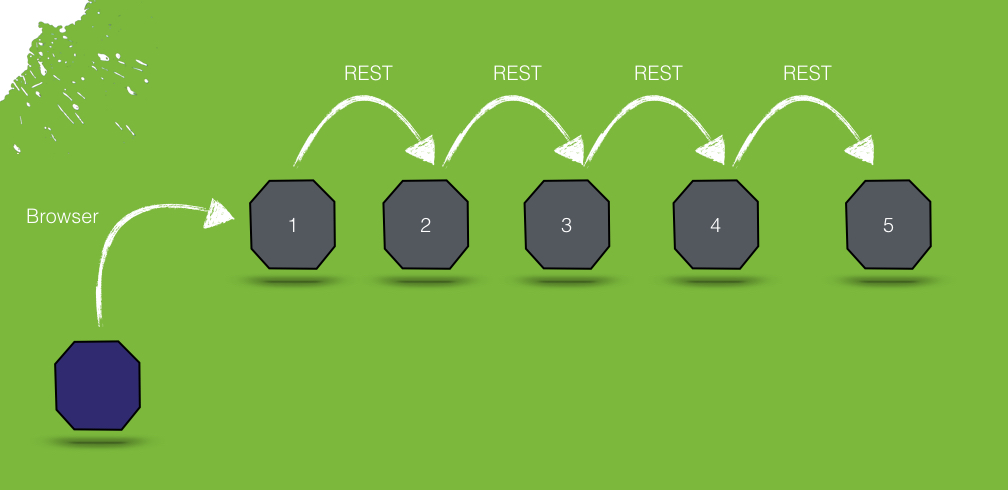
Resilient Software - Willkommen im Chaos
Was passiert, wenn wir einen Service in der Kaskade herunterfahren? Beispielsweise Node-3.
docker service rm service-3Setzen wir anschließend erneut einen Call gegen das Gateway ab.
curl $(docker-machine ip node-1):8080
{
"host": "d6d431be03f4",
"port": 8080,
"correlationId": null,
"responseInfo": {
"host": "65ec48cebf45",
"port": 8080,
"correlationId": null,
"responseInfo": null,
"msg": "Execption: I/O error on GET request for \"http://service-3:8080\": service-3; nested exception is java.net.UnknownHostException: service-3"
},
"msg": null
}%Die Anwendung funktioniert immer noch, zumindest teilweise.
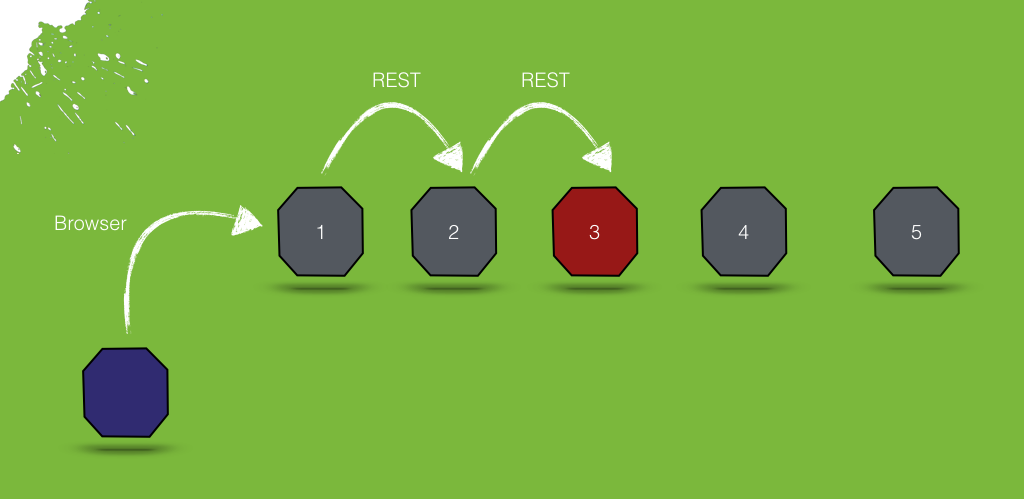
Bringen wir den Service-3 wieder hoch.
docker service create --network test --replicas=2 --name "service-3" -e targetUri=http://service-4:8080 effectivetrainings/rest-cascadePumba Chaos
Die Simian-Army von Netflix ist spezialisiert auf AWS. Im Dockerumfeld gibt es ein schönes kleines Tool namens Pumba, das die Chaos-Konzepte auch in die Docker-Welt bringt.
Pumba bietet hierbei ganz verschiedene Möglichkeiten, die heile Welt durcheinanderzubringen.
Beispielsweise können wir Pumba anweisen, auf jedem Knoten durch Zufall irgendwelche Container herunterzufahren. Hierfür starten wir Pumba als Task auf jedem Knoten (--mode global) und weisen es an, Container zu stoppen (kill)
docker service create --name pumba --mode=global --mount=type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock gaiaadm/pumba:master pumba --random --interval 20s kill --signal SIGTERMEin kleines Video dass Pumba vs. Swarm in Aktion zeigt gibts auf Youtube.
Pumba Chaos - Langsame Verbindung
Pumba kann aber noch mehr Chaos stiften. Wir haben schon simuliert, dass unsere Anwendung so gut eben möglich mit Service-Ausfällen umgehen kann. Was passiert, wenn Services beispielsweise einfach sehr lange brauchen um zu antworten? Mit Docker einfach simulierbar, indem Container pausiert werden.
Pumba kann das auch.
Um die Ergebnisse vergleichen zu können entfernen wir Pumba zunächst wieder und machen einen einfachen Load-Test gegen den gesunden Cluster.
eval $(docker-machine env node-1)
docker service rm pumbaAnschließend entfernen wir alle Replicas, um später auch den Effekt von Replicas bei Timeouts zu beobachten.
for i in {2..4}; do
docker service update --replicas=1 service-$i
done;Jetzt weisen wir Pumba an, statt Container zu stoppen, diese einfach für jeweils 3 Sekunden zu pausieren. Da wir eine Kaskade an Service Calls haben kann sich das zu einem beachtlichen Delay entwickeln.
docker service create --name pumba --mode=global --mount=type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock gaiaadm/pumba:master pumba --random --interval 5s pause --duration 3sIdealerweise testen wir das System direkt, indem wir es ein wenig unter Last setzen. Das geht ganz einfach mit dem Image effectivetrainings/docker-stress, was intern nichts weiter nutzt als Apache Bench.
docker run effectivetrainings/docker-stress -n 10000 -c 4 http://192.168.99.100:8080/ (1)-
Wir feuern 10.000 Requests mit 4 Threads auf das Gateway ab.
Der Test mit 10.000 Requests dauert auf meinem Rechner ca. 1:40 Minuten. Hier das Ergebnis.
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 15 116.8 1 1004
Processing: 7 25 11.4 22 148
Waiting: 7 24 11.4 21 147
Total: 7 39 115.6 23 1030
Percentage of the requests served within a certain time (ms)
50% 23
66% 27
75% 30
80% 32
90% 40
95% 51
98% 76
99% 1001
100% 1030 (longest request)98% der Requests wurden in weniger als 76 ms bearbeitet. 30 Requests waren auffällig langsam. Ursache unklar.
Starten wir Pumba und lassen alle 5 Sekunden einen zufälligen Container pro Host 3 Sekunden pausieren. Die Wahrscheinlichkeit auf einen pausierten Host zu treffen ist also je nach Verteilung der Services auf die nodes recht hoch.
docker service create --name pumba --mode=global --mount=type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock gaiaadm/pumba:master pumba --random --interval 5s pause --duration 3sWir lassen den Stress-Test nochmal laufen. Nach der Verteilung der Node (3 Container pro Cluster) liegt die Wahrscheinlichkeit, einen langsamen Knoten zu treffen bei 30%. Die Wahrscheinlichkeit zwei langsame Knoten zu treffen bei ca 9% und alle drei Knoten bei rund 3%.
|
Caution
|
Die Erwartung wäre also, ca. 60% der Requests sollten im Normbereich liegen, 30% der Requests durchschnittlich 3 Sekunden dauern und ein kleiner Bereich sollte sehr lange dauern (>= 6 Sekunden). |
Der Testlauf braucht unglaubliche 17:49.38 Minuten.
Requests per second: 9.35 [#/sec] (mean)
Time per request: 427.622 [ms] (mean)
Time per request: 106.905 [ms] (mean, across all concurrent requests)
Percentage of the requests served within a certain time (ms)
50% 31
66% 43
75% 53
80% 62
90% 98
95% 4795
98% 5831
99% 7691
100% 12668 (longest request)Tatsächlich sehen wir, dass immer noch 90% der Requests in weniger als 100 ms verarbeitet. 5% der Requests brauchten knapp 5 Sekunden, 1% sogar mehr als 7. der länger Request benötigt 12 Sekunden, hat also evtl. alle drei pausierten Container getroffen.
Replicas
Wir wiederholen das Experiment und geben jetzt aber allen Services jeweils zwei Replicas, wir halbieren damit also die Wahrscheinlichkeit einen langsamen Node zu treffen.
for i in {1..5}; do
docker service update --replicas=2 service-$i
doneStarten wir den Stresstest erneut mit denselben Parametern.
docker run effectivetrainings/docker-stress -n 10000 -c 4 http://192.168.99.100:8080/
Requests per second: 3.18 [#/sec] (mean)
Time per request: 1257.195 [ms] (mean)
Time per request: 314.299 [ms] (mean, across all concurrent requests)
Percentage of the requests served within a certain time (ms)
50% 14
66% 23
75% 1069
80% 2447
90% 4973
95% 7487
98% 10007
99% 10015
100% 14992 (longest request)Nur 75% der Requests konnten unter einer Sekunde ausgeführt werden, 2% (immerhin 200 Requests) brauchten mehr als 10 Sekunden für die Ausführung.
Die Erklärung dürfte im Round-Robin Loadbalancing liegen, das sich anscheinend sehr negativ auf die Performance auswirkt, rechnerisch belegen kann ich das aber nicht.
Pumba Chaos - Netzwerkproblem
Ein sehr sehr spannendes Thema ist für mich der dritte Abschnitt. Dank des Container Network Models von Docker kann man sehr spannende Dinge mit dem Netzwerk machen - beispielsweise in den Traffic eingreifen.
Pumba bietet auch hierfür einige spannende Werkzeuge.
Mit pumba netem können wir: - Pakete verwerfen - Pakete verzögern - Pakete neu ordnen - Pakete duplizieren
Spielen wir das Experiment noch ein letztes Mal durch, starten Pumba und lassen es alle 5 Sekunden für zwei Sekunden 5% der Netzwerkpakete verwerfen.
|
Caution
|
Achtung, damit das funktioniert muss das Tool tc im Container installiert sein. Typischerweise kommt das mit dem Paket iproute2. |
# wieder ohne replicas
for i in {1..5}; do
docker service update --replicas=1 service-$i
done
#remove pumba
docker service rm pumba
#restart with new configuration
docker service create --name pumba --mode=global --mount=type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock gaiaadm/pumba:master pumba --debug --random --interval 5s netem --duration 2s loss --percent 5Ich kann nicht abschätzen, ob das überhaupt irgendwelche Auswirkungen haben wird. Starten wir den Stresstest erneut und vergleichen mit der ursprünglichen Annahme.
docker run effectivetrainings/docker-stress -n 10000 -c 4 http://192.168.99.100:8080/
Time per request: 82.795 [ms] (mean)
Time per request: 20.699 [ms] (mean, across all concurrent requests)
Percentage of the requests served within a certain time (ms)
50% 23
66% 30
75% 35
80% 40
90% 54
95% 76
98% 243
99% 1014
100% 10225 (longest request)
Complete requests: 10000
Failed requests: 3880Der Testlauf dauerte ca. 3:40min.
Starten wir Pumba erneut aber diesmal mit 50% Loss.
#remove pumba
docker service rm pumba
#restart with new configuration
docker service create --name pumba --mode=global --mount=type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock gaiaadm/pumba:master pumba --debug --random --interval 5s netem --duration 2s loss --percent 50
docker run effectivetrainings/docker-stress -n 10000 -c 4 http://192.168.99.100:8080/
Complete requests: 10000
Failed requests: 9329 (1)
(Connect: 0, Receive: 0, Length: 9329, Exceptions: 0)
Percentage of the requests served within a certain time (ms)
50% 18
66% 25
75% 32
80% 37
90% 58
95% 98
98% 1018
99% 3006
100% 12490 (longest request)Die Fehlerrate ist verheerend
Fazit
Chaos-Testing macht Spaß. Mit Pumba lassen sich erstaunliche Dinge machen. Stress-Testing / Chaos-Testing macht definitiv Sinn. Ich würde es wahrscheinlich nicht in Produktion machen - wohl aber beispielsweise auf einer Testumgebung.
Cleanup
Damit ist das Experiment beendet und wir verwischen alle Spuren.
docker service rm pumba
for i in {1..5}; do
docker service rm service-$i
done
docker service rm viz
docker network rm test
docker-machine rm node-1 node-2 node-3Docker Training
Wollen Sie mehr erfahren? Ich biete Consulting / Training für Docker. Schauen Sie doch mal vorbei!